Your recruiting deserves
better evaluation
AI-era talent
evaluated in a new way
Don't measure tool fluency — measure the thinking: how someone explains a problem to AI, validates the output, and chooses the right tool. Beyond the deliverable, “how they solved it” is captured automatically, so reviewers can see the whole process at a glance.
What are you looking at
to hire AI talent today?
What makes a good AI hire, what 'using AI well' actually means, how much AI literacy the people evaluating themselves should have — none of it is clear.
“No AI hiring profile”
Because each company and role needs different AI abilities, there's no agreed-upon, universal definition of an AI hire.
“No yardstick for 'good with AI'”
Shipping code fast isn't the same as using AI well. You need a measure of what to look for, and how far it should go.
“I'm a reviewer, but I barely know AI”
If the people evaluating aren't comfortable with AI tools and environments, they can't read the real gap between candidates.
Defining AI talent, setting the bar, automating assessment —
all in one module
Probe gives recruiters an AI hiring standard, co-authors the problems with them, and runs an automated evaluation.
Usecase
The future of hiring evaluation,
built with an AI-first company
Probe is in production as Krafton's standard hiring assessment. From researchers and engineers to non-developer and back-office roles, Probe delivers trusted tests and assessment reports aligned to Krafton's Vision & Value.
AI-native hiring know-how
Krafton's criteria and methods for hiring at the AI frontier — packaged in.
In production, expanding
Krafton itself is rolling AI capability assessment across more and more roles.
Our Goal
Define AI literacy,
rewrite what evaluation means
Define AI literacy clearly, then provide differentiated standards and methods to measure it. Make 'good with AI' something you can actually compare.
What is AI literacy?
- 01
Model literacy
Which models and tools to call, and how to prompt them.
tool · prompt - 02
Environment literacy
Understanding the layer around the model — Memory, MCP — and configuring it for the task.
memory · MCP · harness - 03
System literacy
Beyond one-off calls — wiring AI into the full workflow.
end-to-end · automation
How it works
Candidates solve;
reviewers see the process
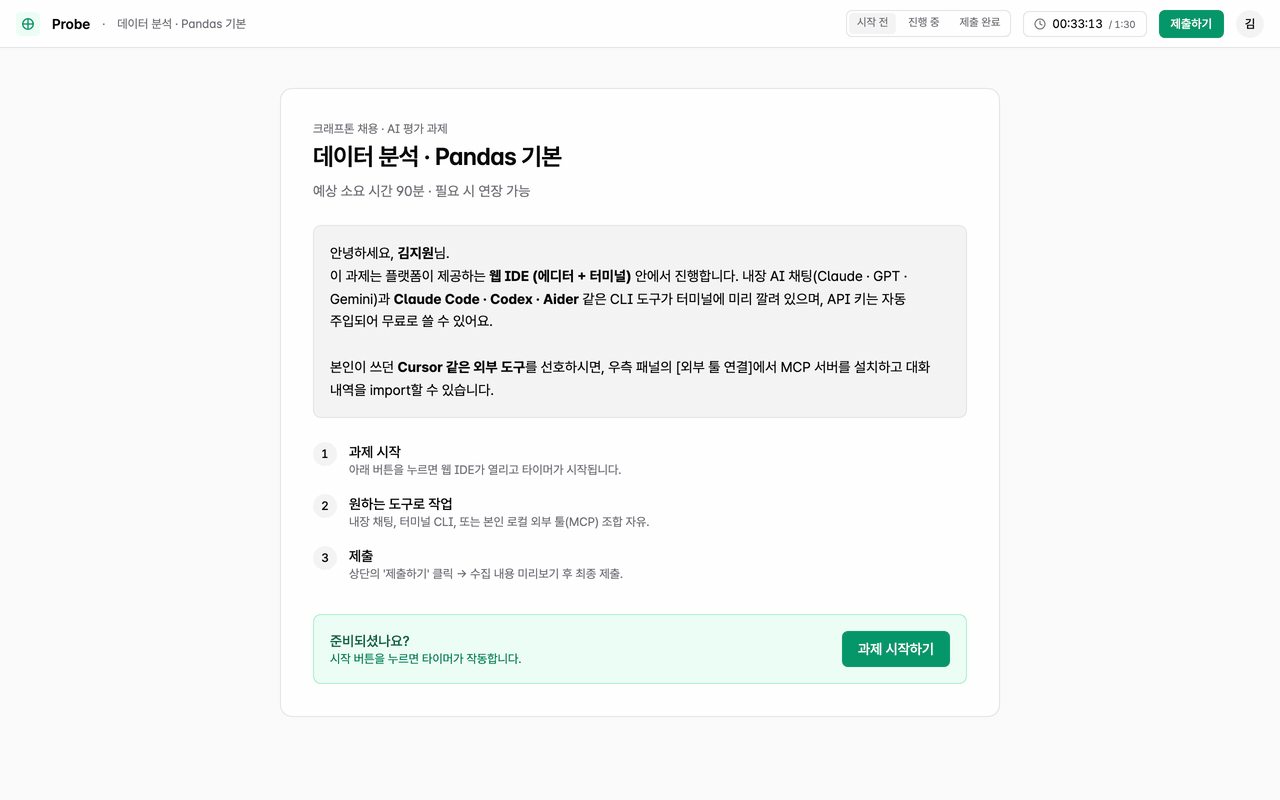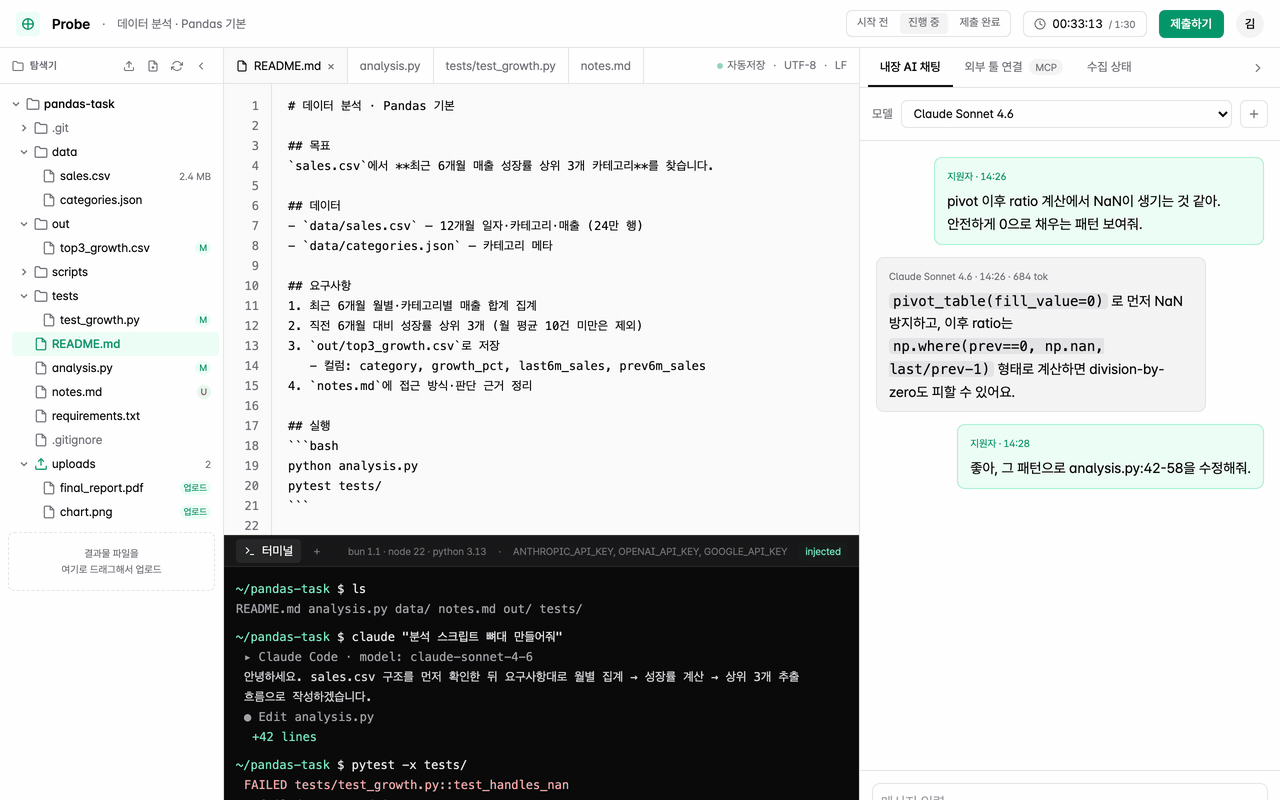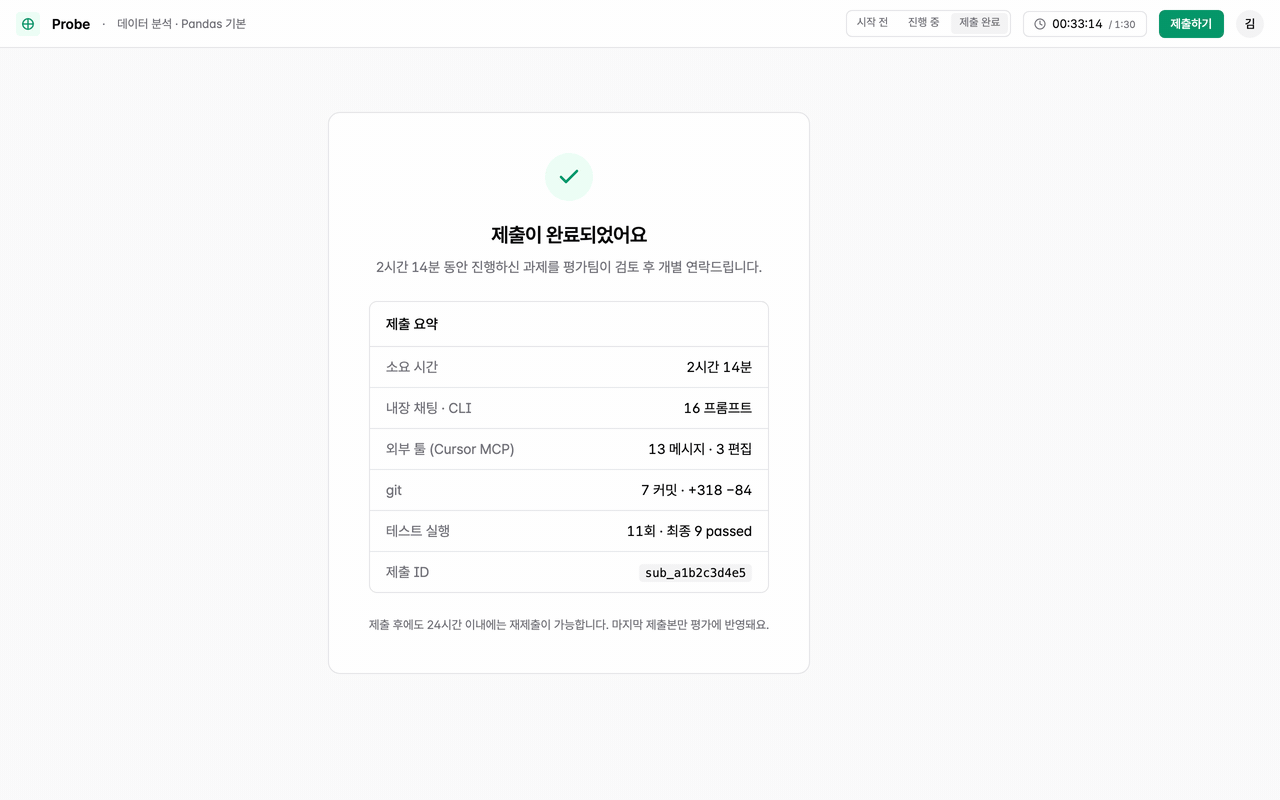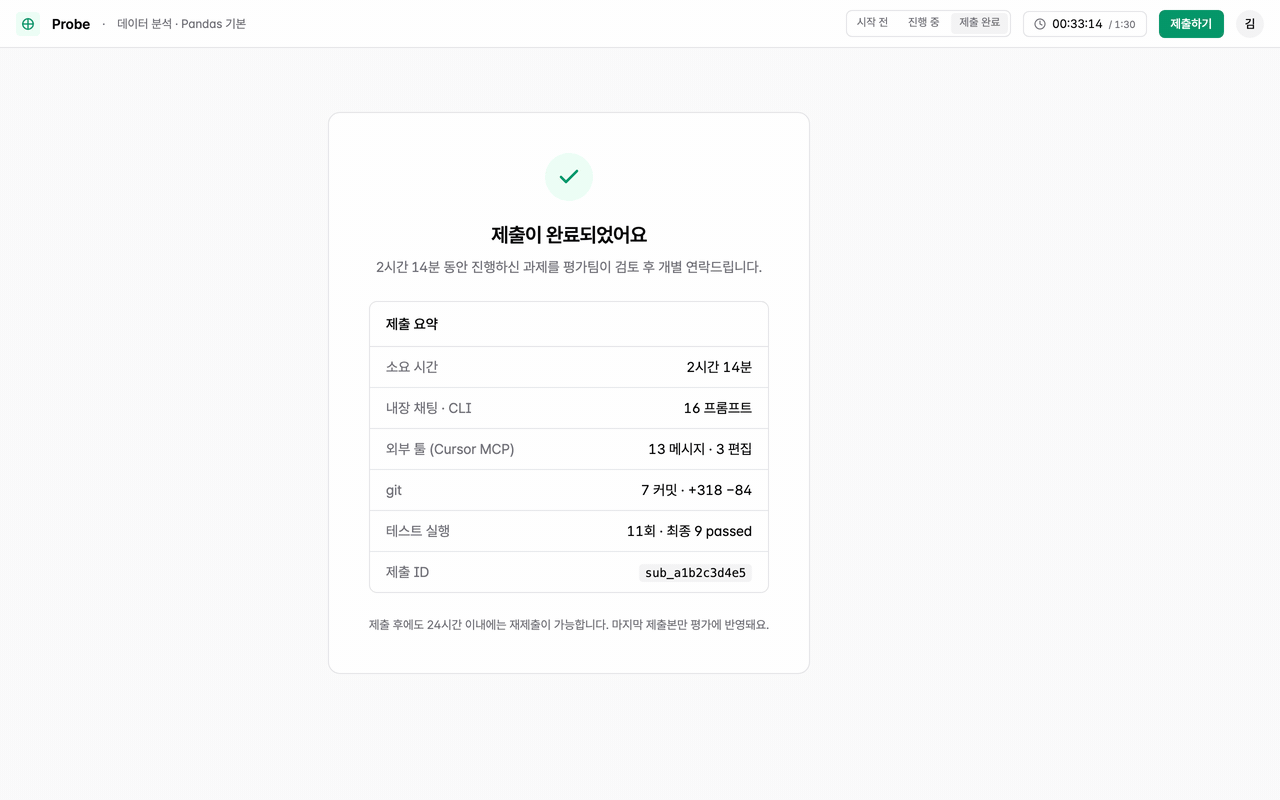
Candidates get a smooth task environment; reviewers get the deliverable plus a timeline on one screen. Neither side has to write extra narrative.
- Step 1
Task starts
Open the browser IDE and start solving. Built-in chat and terminal, plus top models provided free.
Web IDEBuilt-in AI modelsConnect external tools via MCP - Step 2
Process auto-captured
Prompts, tool switches, test runs, and git diffs are all recorded on the timeline. No write-up required from the candidate.
Prompt logTool switchingTest resultsgit diff - Step 3
Reviewer
Deliverable + per-area evaluation and report + reviewer's qualitative notes — provided together on one screen.
Timeline viewPer-area scoringTags & notes
Evaluation areas
We evaluate, area by area
We map signals an evaluator can read from automatic capture vs. signals that need a human reviewer — separately, per area.
Problem framing
Track decomposition of requirements in the initial prompt and how sub-questions are split.
- # of decomposition steps
- Sub-question split pattern
- Whether constraints/assumptions are stated
Prompt design
Whether constraints and output format are specified, context attached, and system prompt used.
- Output format specified
- Context attached
- System prompt usage
Validation · critical thinking
Follow-up rate, edits to AI output, edits before paste, test re-runs.
- Follow-up rate
- AI output edit count
- Edits before paste
- Test re-runs
Tool use efficiency
Model choice patterns, tool switch frequency, completeness vs. prompt count.
- Model choice patterns
- Tool switch frequency
- Completeness vs. prompts
Final output
git diff, test pass rate, and the result file — read directly. No automatic scoring.
- git diff
- Test pass rate
- Result file
Timeline integration
Per-area logs in chronological order on one screen. Click an event → jump to the original prompt/diff/log.
- Event → original jump
- 1–5 scoring per area
- Tags & notes
Same starting line for everyone
and we focus on the problem-solving process
During the assessment we provide top Claude, OpenAI, and Gemini models for free. We also place no caps on model power or scope — candidates get the same freedom they'd have in real work.
- ASame environment
Candidate A
· No paid subscriptionClaudeGPT-5Gemini Pro - BSame environment
Candidate B
· Cursor Pro userClaudeGPT-5Gemini Pro - CSame environment
Candidate C
· First time with AI toolsClaudeGPT-5Gemini Pro